
Key takeaways
- Retrieval quality often beats upgrading the LLM
- Attach permissions metadata to every chunk
- Measure hit rate and latency per pipeline stage
- Cache embeddings and pre-generate where personalization allows
- Run offline eval sets before scaling document volume
- Operate corpora with admin visibility and explicit versioning
Article content
RAG sounds simple until users ask real questions
Retrieval-augmented generation promises grounded answers: embed documents, retrieve relevant chunks, pass them to an LLM, and reduce hallucinations. In practice, RAG systems fail quietly - wrong chunks rank higher than correct ones, stale content misleads users, and latency stacks up across embedding, search, and generation steps. SparkScribe has shipped RAG pipelines for consumer AI products, B2B knowledge bases, and internal copilots. The lessons repeat regardless of industry.
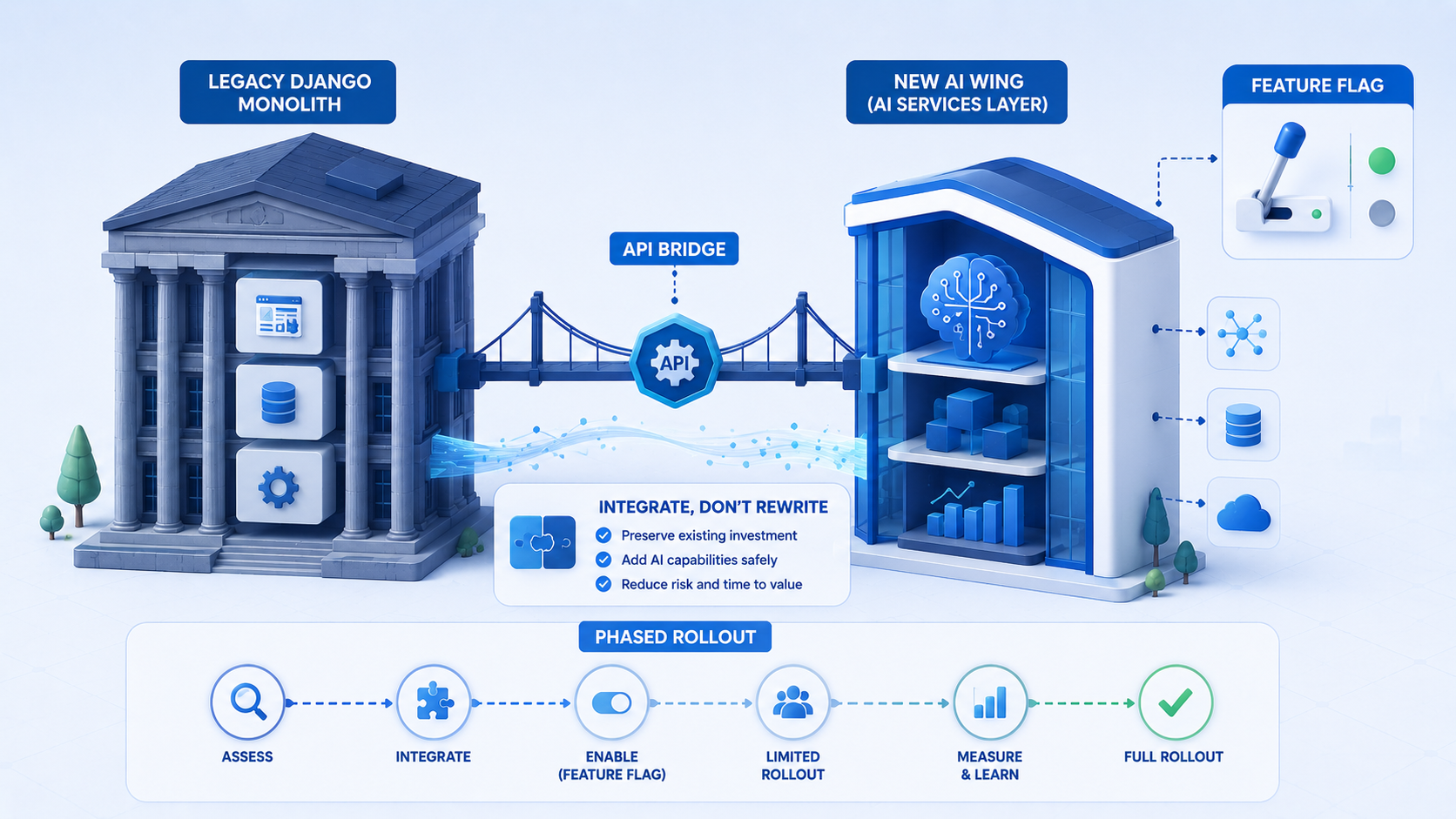
Django remains our default orchestration layer. It manages document ingestion, user sessions, access control, caching, and admin tooling while specialized vector stores handle similarity search. The split keeps product teams in familiar territory while allowing search infrastructure to evolve independently.
Lessons from a consumer AI platform
On AstroSure.ai, we built personalized astrology guidance powered by LLMs. RAG entered the picture for contextual readings drawn from structured chart data, curated content libraries, and user history - not a generic FAQ bot, but a system where retrieval quality directly affected user trust and retention.
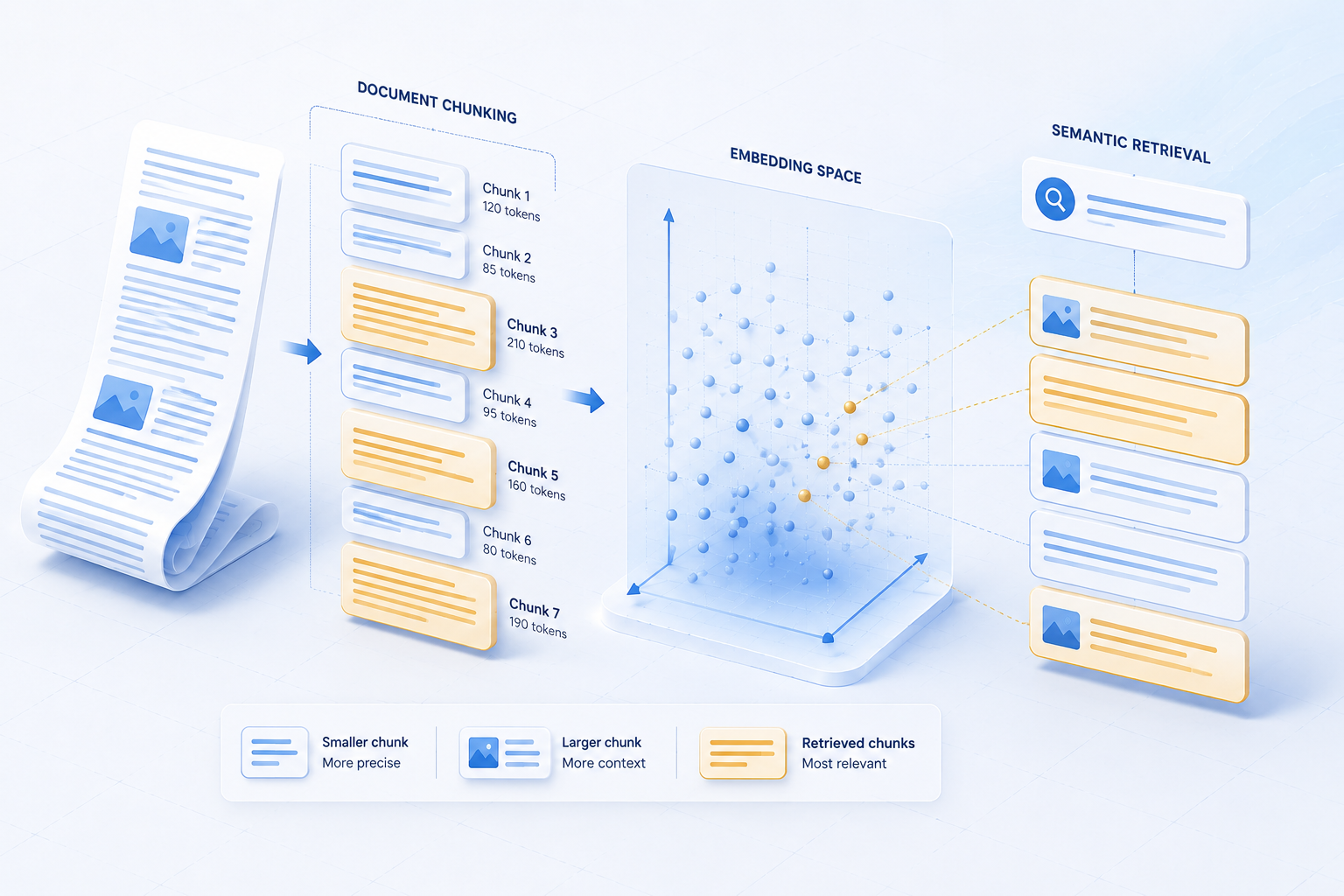
Three early mistakes taught us the most. First, we initially chunked content by fixed token size without respecting semantic boundaries; readings pulled fragments that read oddly out of context. Second, we under-invested in freshness signals - daily content needed explicit TTL and re-embedding jobs. Third, we measured answer fluency more than retrieval precision; users noticed wrong context faster than awkward phrasing.
Architecture that survived production traffic
We settled on a pipeline with clear stages: ingest → normalize → chunk with metadata → embed → index → retrieve with filters → rerank → generate → validate. Each stage emits metrics. Celery workers handle ingestion and re-embedding; the request path stays read-heavy with aggressive Redis caching for repeated daily queries.
Access control lives in Django, not in the vector store alone. User A should never retrieve chunks scoped to User B even if embeddings sit in a shared index. We attach tenant and permission metadata to every chunk and apply filters before similarity search runs.
Retrieval quality beats model upgrades
Teams often reach for a larger model when answers disappoint. More often, the fix is better chunks, hybrid search (dense plus keyword), or a cross-encoder reranker. We run offline eval sets: curated questions with expected source documents. When retrieval hits the right chunk in the top three results, generation quality jumps - even with a mid-tier model.
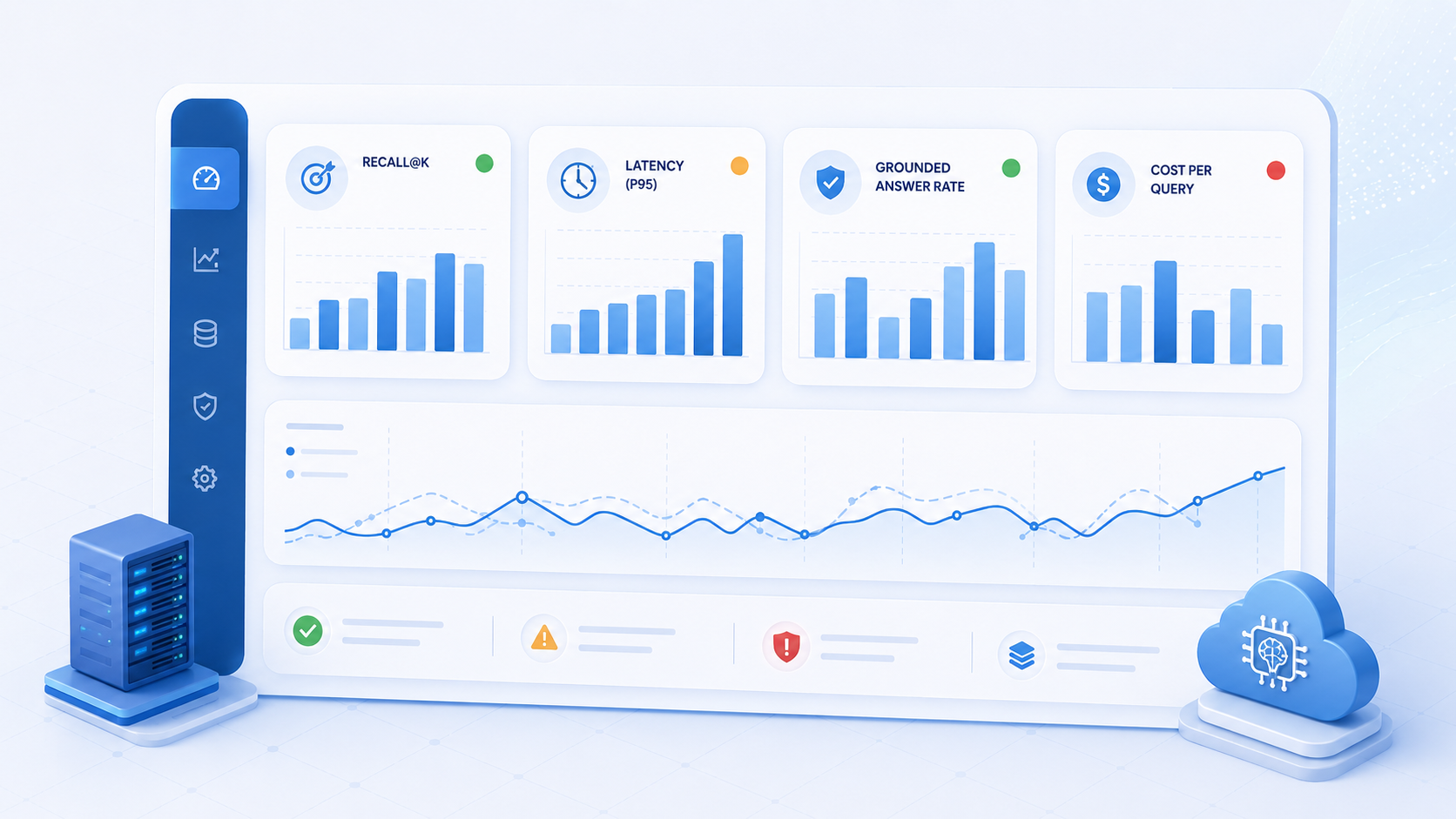
Monitoring must include retrieval metrics: hit rate, mean reciprocal rank, empty-result rate, and latency per stage. Pair these with user thumbs-down events tied back to retrieved chunk IDs so content teams know which sources to fix.
Cost and latency under real load
RAG adds multiple billable steps. Embedding every query on each request gets expensive fast. Cache query embeddings for common questions, precompute embeddings for static corpora, and batch ingestion jobs during off-peak hours. For consumer apps with daily repeat content, pre-generate and cache final responses where personalization allows.
Set token budgets on retrieved context. More chunks is not better - noise confuses models and inflates cost. We typically start with five to eight chunks after reranking, then tune based on eval data.
Operating RAG as a product subsystem
Non-engineers need visibility. Django admin views for document status, last embedded at, error logs, and flagged answers keep support and content teams effective. Version corpora explicitly so rollbacks do not require emergency deploys.
For US and UK clients, document retention and PII handling belong in the ingestion contract. Strip sensitive fields before embedding, honor deletion requests across indexes, and document which regions store vectors.
Starting small without painting yourself into a corner
Launch with a bounded corpus, hybrid search, and rigorous eval before scaling document volume. Our LLM & RAG development engagements usually begin with a two-week retrieval audit: baseline metrics, chunking fixes, and a roadmap for production hardening.
RAG in production is an operations problem as much as a modeling problem. Teams that plan for freshness, access control, and measurement early ship experiences users trust - not demos that collapse under the first marketing push.
Choosing embedding models and chunk strategies together
Embedding model upgrades require re-indexing - budget time and compute before switching vendors. Evaluate new models against your offline question set; marginal generic benchmark gains may not translate to your domain vocabulary. Chunk overlap, heading-aware splits, and metadata such as product area or document type often outperform chasing the latest embedding release without corpus-specific tuning.
For multilingual US and UK audiences, confirm retrieval handles locale-specific terminology and date formats in filters. Django locale middleware and explicit language tags on chunks prevent cross-language retrieval mistakes that fluent LLM prose can hide until a user notices factual drift.
Handoff between data science and product engineering
RAG quality improves when content owners and engineers share ownership. Weekly reviews of thumbs-down clusters, empty retrieval logs, and support tickets mentioning “wrong answer” keep the corpus honest. Django admin dashboards surfacing chunk age, source URL, and last verification date empower non-engineers to fix content without opening Jupyter notebooks.
SparkScribe often staffs delivery with both backend engineers and a part-time eval owner during RAG launches - a pattern consumer platforms like AstroSure benefited from when daily content freshness was as critical as model selection.
Further reading

RAG production metrics we track weekly
| Metric | Why it matters | Typical action trigger |
|---|---|---|
| Retrieval hit@3 | Grounding quality | Below 80% → revisit chunking or reranker |
| P95 retrieval latency | User experience | Above 400ms → cache or index tuning |
| Stale chunk rate | Content trust | Any daily content past TTL → fix jobs |
| Cost per answered query | Unit economics | Spike → reduce context or cache embeddings |
| Thumbs-down with chunk ID | Actionable QA | Cluster by source document → content fix |
Which vector database should we use with Django?
We have shipped with pgvector, Pinecone, and Weaviate depending on scale and ops appetite. For many B2B apps, pgvector inside PostgreSQL reduces moving parts.
How often should we re-embed content?
Whenever source documents change materially or on a schedule aligned with content freshness - daily for news-like data, weekly or on publish for stable knowledge bases.
Can RAG replace fine-tuning?
Often for factual Q&A over proprietary docs, yes. Fine-tuning still helps for tone, format, or domain reasoning that retrieval alone cannot supply.
What broke first on AstroSure under load?
Unbounded context sizes and missing caches on repeated daily queries. Fixing retrieval filters and response caching mattered more than switching LLM providers.
Building a consumer or B2B RAG feature? Read the full AstroSure case study or talk to us about a retrieval audit.