Key takeaways
- Rank use cases by pain and revenue not hype
- Introduce AI through explicit Django service interfaces
- Roll out read-only features before any automated writes
- Enforce existing auth rules on every retrieval path
- Measure edit rate and task completion not vanity clicks
- Replace subsystems surgically when needed not whole platforms
Article content
Your web app works - don't throw it away for AI
Founders hear that AI requires a platform rewrite: new stack, new team, new timeline. Usually that is wrong. SparkScribe regularly adds LLM features to existing Django applications - copilots, summarization, classification, retrieval over company documents - without discarding years of domain logic, permissions, and integrations.
The rewrite temptation is understandable when prototypes use frameworks unrelated to your production code. The disciplined path integrates AI at clear boundaries, validates value with real users, and expands only where metrics justify deeper investment.
Audit before you architect
Start with use cases ranked by user pain and revenue impact, not technology excitement. For each use case, document inputs, outputs, latency tolerance, error cost, and data sensitivity. A support ticket summarizer tolerates different failure modes than an automated billing adjustment agent.
Inventory existing assets: PostgreSQL content, PDFs in S3, CRM webhooks, admin workflows. AI features fail when data is siloed or dirty - cleanup often dominates calendar time more than model selection.
Integration patterns that fit Django
- Read-only assistants: Sidebar or modal calling a service that retrieves context and streams responses - no database writes initially.
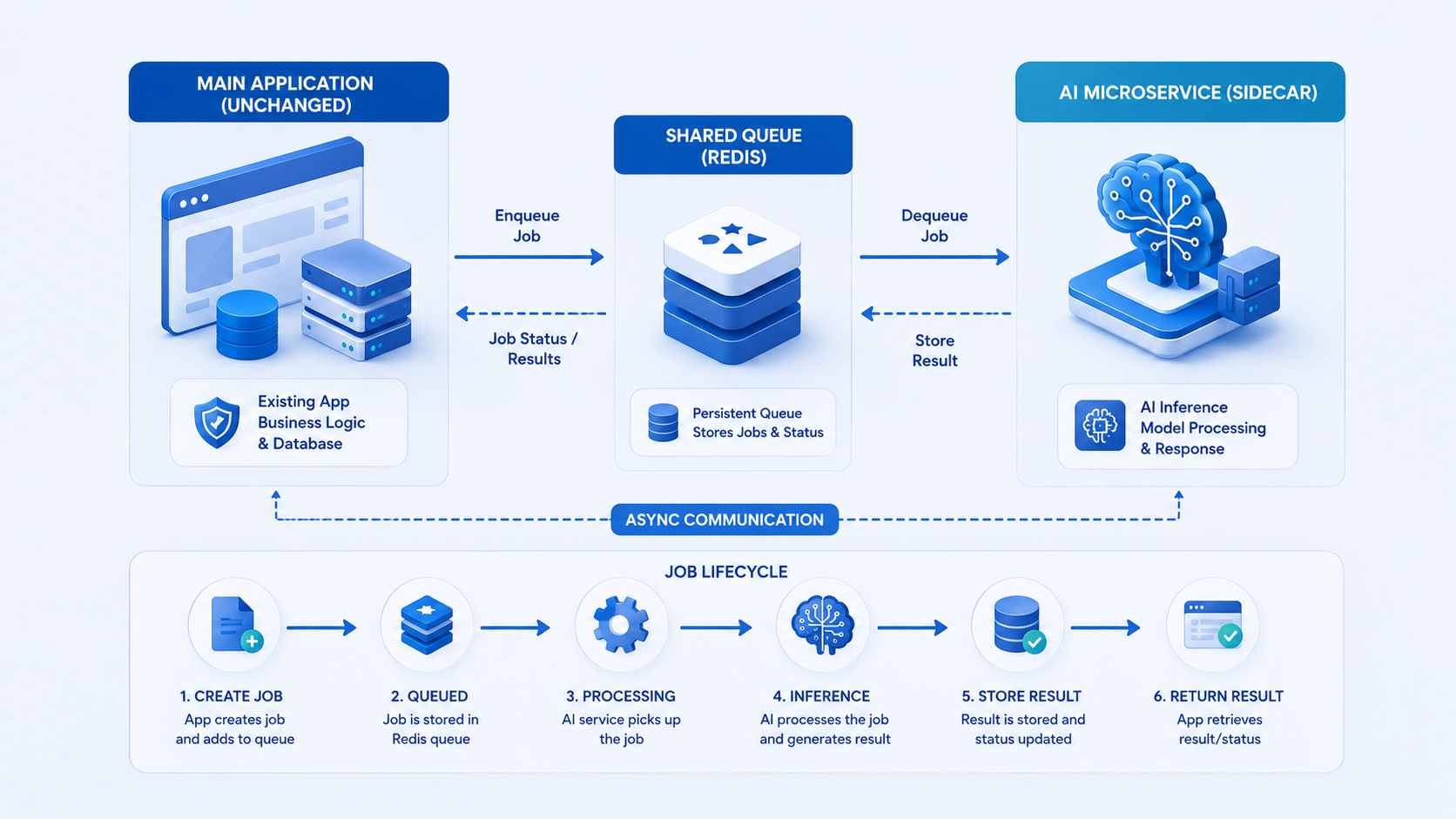
- Background enrichment: Celery jobs classify leads, tag documents, or generate drafts humans approve in admin.
- Search upgrade: Hybrid RAG over existing models with embeddings stored alongside current records.
- Workflow copilots: Multi-step agents invoking whitelisted Django services with audit logs.
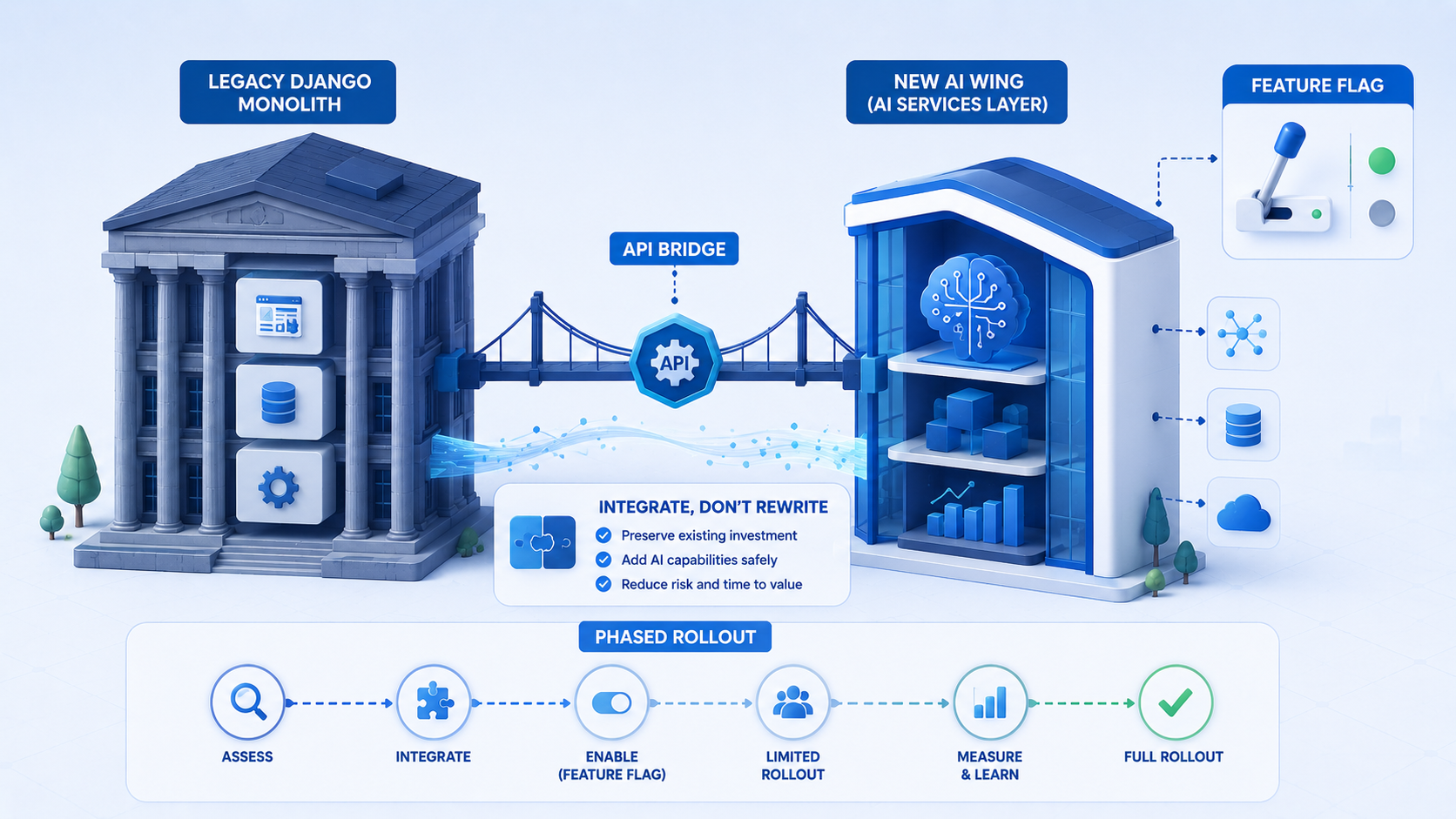
Boundary layers keep legacy safe
Introduce an AI service module with explicit interfaces: generate_summary(document_id), suggest_reply(ticket_id). Views and serializers call these functions; they do not embed prompts inline. Swap models or providers without touching UI code.
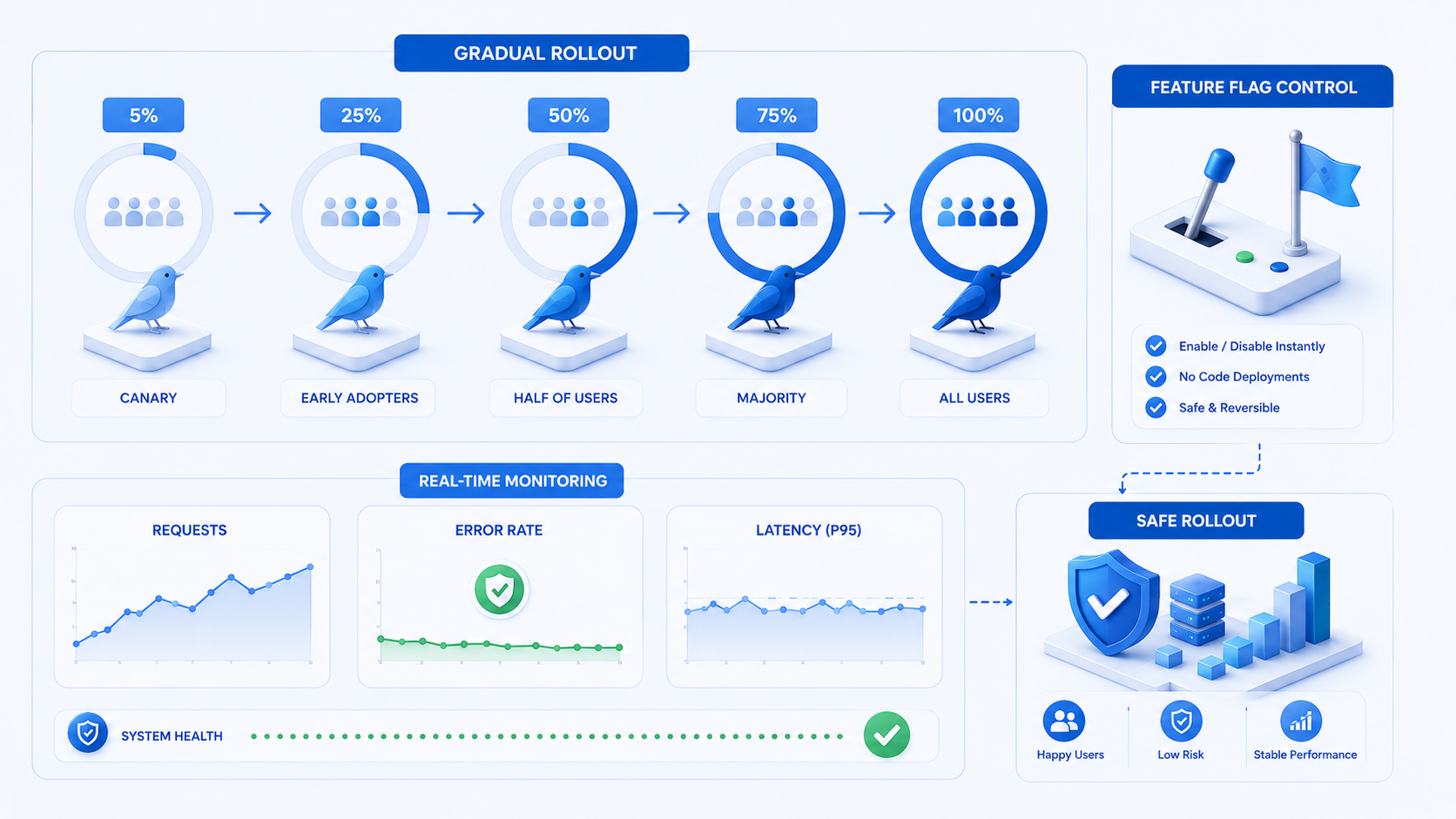
Feature flags control rollout per tenant or user cohort. Kill switches prevent runaway costs if a provider spikes pricing or a prompt regresses.
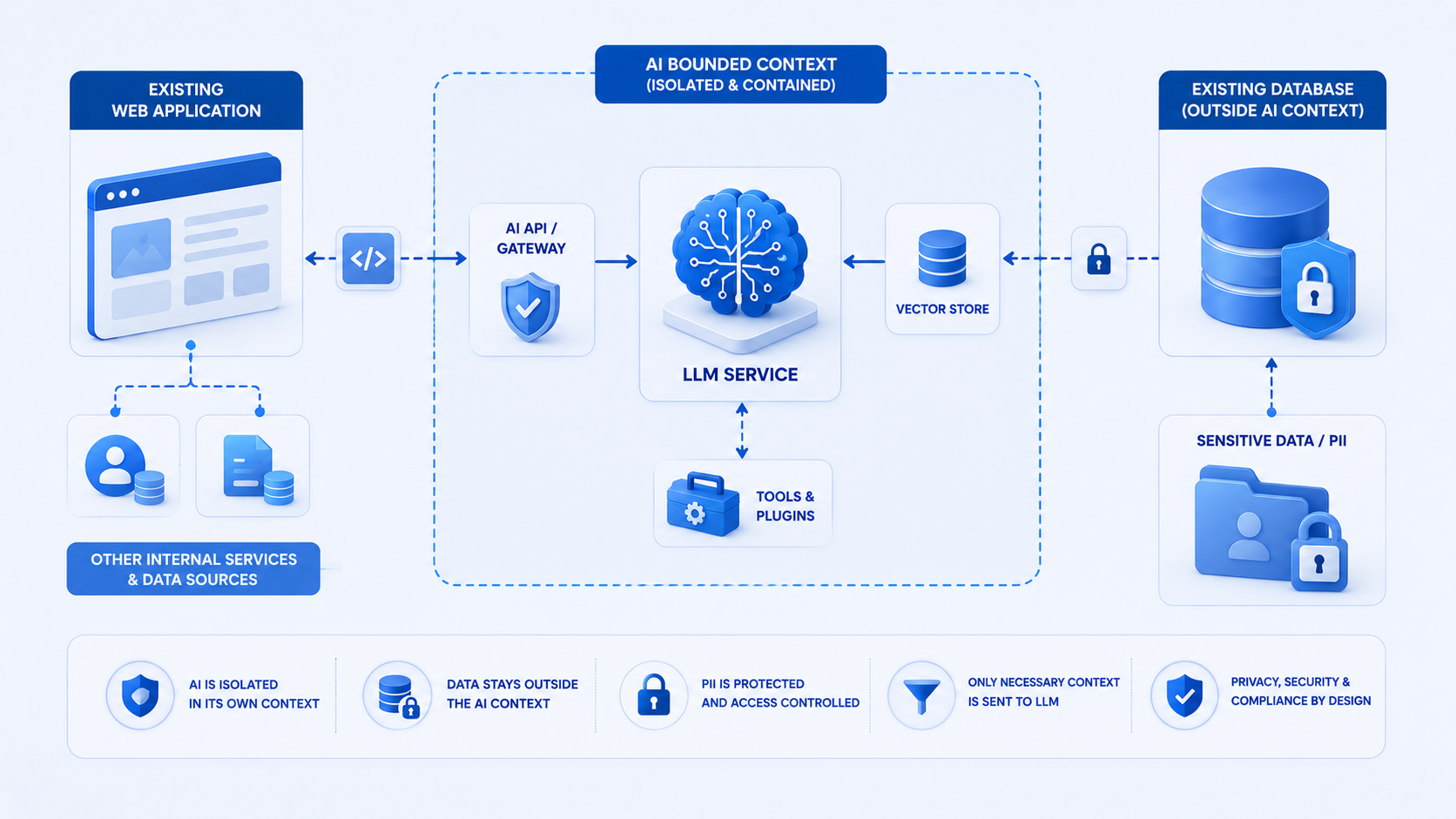
Data and compliance on existing apps
Your app already enforces auth - AI must respect the same rules. Retrieve documents through Django querysets, not raw vector indexes bypassing permissions. Log prompts and responses with retention policies aligned to GDPR or client contracts.
For US and UK customers, disclose AI-assisted features in product copy and terms where required. Human review gates remain appropriate for regulated advice, financial calculations, or medical adjacency.
Phased rollout we recommend
Phase one: internal admin users only, read-only outputs, heavy logging. Phase two: selected beta customers with feedback widgets. Phase three: general availability with cost controls and SLAs. Skipping phases turns production users into unpaid QA.
Measure task completion time, edit rate on AI drafts, and support escalation rate - not vanity engagement metrics alone.
When a partial rewrite makes sense
Sometimes subsystems deserve replacement - a brittle Node microservice nobody maintains, or a search stack that cannot support embeddings. Replace surgically, not holistically. Django as system of record often stays while adjacent services upgrade.
Get a migration-free AI roadmap
SparkScribe assesses existing Django codebases for AI readiness in fixed-scope engagements. See AI integration services, review client examples, and reach out with your stack and top three use cases.
Technical prerequisites that accelerate integration
Clean separation between views and business logic, existing Celery infrastructure, centralized logging, and feature flag hooks reduce AI integration time dramatically. Codebases with god views and inline SQL still work - but budget extra weeks for refactoring before agents touch side effects. A one-week architecture cleanup often pays for itself by preventing duplicated prompt logic across endpoints.
Document your current data retention policies before connecting external model providers. Sometimes the correct first step is anonymization pipelines or on-prem inference options rather than sending raw customer content to third-party APIs. Django management commands and admin actions can power human review queues while you validate quality.
Organizational change management
Support and operations teams need training on when AI assists versus when humans must decide. Product copy should set expectations - AI suggestions, not guarantees. Internal champions on the client side who celebrate early wins and report failures constructively keep rollout momentum. Technology without adoption planning yields unused features and skeptical leadership.
SparkScribe often pairs engineering delivery with short enablement sessions for client success teams - how to interpret confidence scores, escalate bad outputs, and feed corrections back into eval datasets. That loop improves models and processes together.
Vendor and model lock-in risks
Abstract provider interfaces early so switching LLM vendors does not require rewriting UI layers. Store prompts and eval datasets in your infrastructure, not solely inside a third-party prompt UI. For regulated clients, document subprocessors and maintain contracts allowing audit of data flows - Django settings and environment-based provider keys make multi-vendor staging straightforward when negotiated upfront.
Success metrics for incremental AI adoption
Define baseline metrics before enabling AI: support handle time, content production hours, conversion on assisted flows. Compare after each rollout phase with cohort controls where possible. Leadership responds to numbers more reliably than anecdotal demo excitement - especially when board members ask whether AI investment paid off.
Further reading

If your AI pilot requires a full rewrite, the pilot is probably scoped wrong. Prove value on read-only paths first, then expand write access deliberately.
Will AI slow down our existing app?
Async jobs and streaming responses keep web requests fast. Heavy work belongs in Celery, not synchronous views.
Do we need a vector database on day one?
Not always - start with PostgreSQL full-text search or pgvector if corpus size is modest. Scale storage when retrieval metrics demand it.
How do we control OpenAI costs?
Per-user rate limits, cached responses, smaller models for classification, and billing alerts on daily spend thresholds.
Can AI write to our database safely?
Yes, through reviewed service functions with validation - never free-form SQL generation from model output.
Adding AI to a live product? Book an integration assessment with our Django AI team.


