


AI Automation
Workflow automation with LLMs, logging, cost caps, and review UIs. Integrations with tools you already use.
View AI Automation service detailsProduct
Backend
Frontend
AI
Cloud
Care
AI & digital
Commerce & retail
Enterprise & HR
Hospitality & healthcare
Media & fintech
Credentials & field services
RAG · Embeddings · Evals
Private document Q&A with citations, evals, and permission boundaries.
Support and legal teams cannot trust RAG that hallucinates sources. We require citations, confidence rules, and abstain paths.
Permission boundaries must filter retrieval per user and tenant before PDFs are embedded.
Tables, scans, and mixed layouts need eval on real corpora, not demo markdown files.
Enterprise buyers ask where embeddings live. We document deploy options and NDA-aligned data paths upfront.
Founder-led engineers in Surat (IST) with morning and end-of-day updates so distributed product owners stay in the loop.
RAG sounds simple until your PDFs are messy and answers hallucinate in front of customers. We chunk, embed, retrieve, and cite, with eval sets so you know when quality drops.
Private document Q&A for support, legal, and ops teams is our sweet spot.
Support, legal, and ops teams drowning in internal PDFs.
We build chunking, embedding, and retrieval pipelines with eval harnesses on your documents, not generic blog posts. Answers cite sources or abstain when confidence is low.
RAG for internal knowledge needs logging, cost caps, and deploy paths your security team can review. We document VPC, key management, and data retention before indexing sensitive files.
Vertical experience from shipped products, not generic claims.
Six reasons founders and product leads pick us over a generalist shop - scoped to how we deliver this engagement.
Parsing, chunking, and metadata tuned to your files.
Retrieval limits, prompts, and human review paths.
Golden questions tracked weekly on staging.
Cited answers for ops teams, not toy chatbots.
Golden sets and abstain rules before real users hit the feature.
CRM, docs, and tickets - not a standalone chat box nobody adopts.
How we ship retrieval systems that cite sources and know when to abstain.
We document inputs, outputs, escalation paths, and data boundaries before any model keys go live. Cost caps and human review rules agreed in writing, not as a post-launch patch.
Model routing, retrieval strategy, golden test sets, and per-tenant spend limits defined upfront. Evaluation criteria signed off before pilot traffic hits staging.
Human-in-the-loop UI, logging, and token budgets on staging - real CRM, docs, and ticket integrations. Not notebook demos that break when production traffic arrives.
Abstain rules, fallback models, rate limits, and audit trails reviewed with your team. Failure modes and escalation paths tested before full rollout.
We document inputs, outputs, escalation paths, and data boundaries before any model keys go live. Cost caps and human review rules agreed in writing, not as a post-launch patch.
Model routing, retrieval strategy, golden test sets, and per-tenant spend limits defined upfront. Evaluation criteria signed off before pilot traffic hits staging.
Human-in-the-loop UI, logging, and token budgets on staging - real CRM, docs, and ticket integrations. Not notebook demos that break when production traffic arrives.
Abstain rules, fallback models, rate limits, and audit trails reviewed with your team. Failure modes and escalation paths tested before full rollout.
Tools and runtimes we use on this type of engagement - chosen for production delivery, not slide-deck logos.
Human escalation UI for high-stakes model outputs.
Token spend and error rates visible to your team.
Fast loop when models drift or integrations fail.
Golden questions updated as product scope evolves.
Model routes and prompt versions toggled without redeploying the whole app. Roll back a bad prompt in minutes, not hours.
Per-tenant and global token limits enforced before production traffic. Finance sees dashboards, not surprise invoices.
Prompt and tool-call history retained per your policy and NDA. Retention windows and redaction rules documented at launch.
Human approval on outputs above your risk threshold. Escalation UI wired before autonomous paths go live.
Metrics from shipped products and active engagements - not slide-deck claims.
Real products we shipped for founders in the US, UK, and Europe.
Ops and product leaders want evidence we ship LLM features with guardrails - logging, cost caps, and human review - not notebook demos.
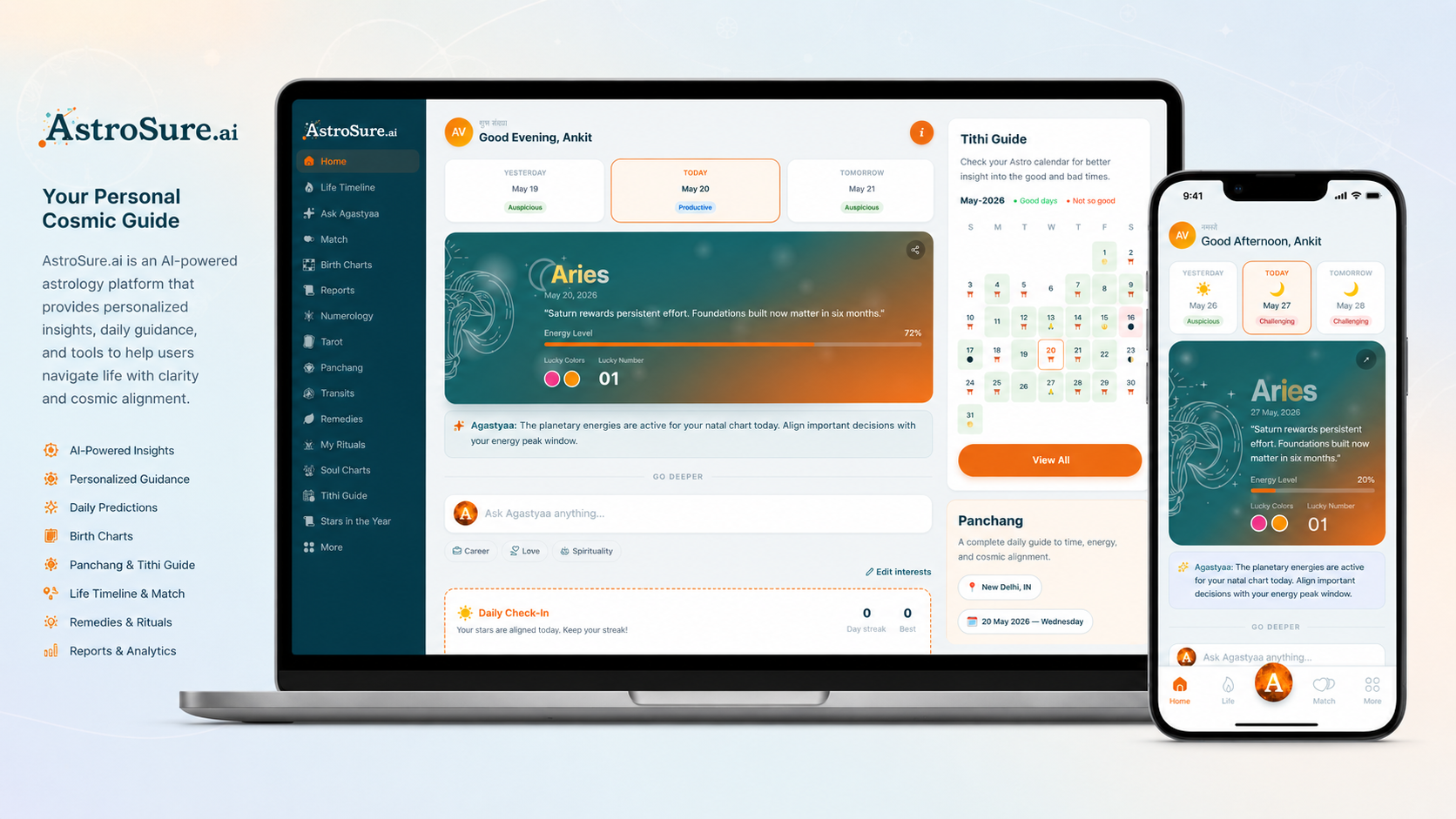
AstroSure shows LLM features with structured data, review paths, and cost controls.
We ship token budgets and logging before real users - patterns reused below.
Case studies include escalation UI and audit trails, not fully autonomous agents.
LLM and RAG builds with fixed eval milestones before production traffic.
Discovery, written requirements, and milestone billing. Best for MVPs, redesigns, and integrations with a defined end state.
A focused engineering squad on your product: weekly demos, shared backlog, and one accountable team when scope evolves.
Smaller monthly hour buckets for fixes, dependency updates, and enhancements, with the same engineers when possible.
What prospects ask on a first call about this service: scope, timelines, fit, and how we work.
5 questions
Corpus boundaries, citation requirements, eval sets, and human review for high-risk answers are defined upfront.
Based on scale, ops appetite, and metadata needs. We document swap costs so you are not locked blindly.
Golden questions, failure sampling, and latency/cost dashboards on staging with your subject-matter experts.
Yes. Retrieval filters by tenant and role are designed with your auth model, not bolted on after.
Ingestion jobs, chunk versioning, and re-index strategy are part of delivery, not a surprise maintenance bill.
Share document sources, privacy rules, and acceptable latency. We prototype chunking and evals in staging before you expose answers to customers.
