Key takeaways
- Treat LLM output as untrusted input until validated
- Keep agent orchestration in services, not views
- Whitelist tools and enforce Django permissions on every call
- Version prompts and log enough metadata to replay failures
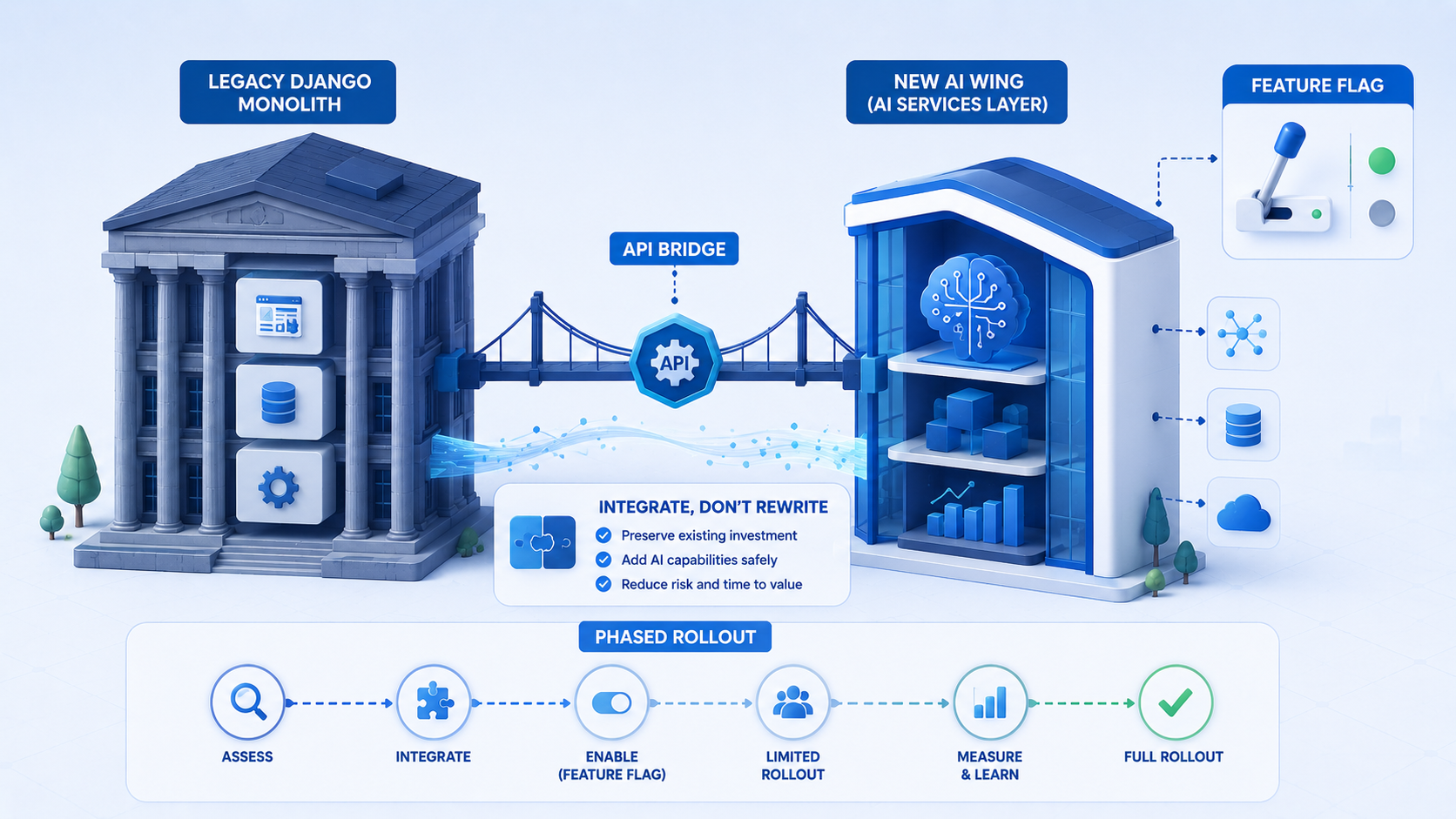
- Use feature flags and canaries for prompt rollouts
- Invest in harness engineering before agents write to production data
Article content
Why harness engineering matters for Django teams shipping AI
Most Django teams can prototype an LLM feature in a weekend. The hard part is making that feature safe, observable, and maintainable when real users - and real money - depend on it. At SparkScribe, we use the term harness engineering to describe the scaffolding around AI agents: guardrails, evaluation loops, structured logging, human-in-the-loop checkpoints, and deployment patterns that treat model output as untrusted input until proven otherwise.
Django is an excellent foundation for this work. Its mature ORM, admin interface, permission system, and background job ecosystem (Celery, Django-Q, or RQ) give you the same primitives you already use for billing, notifications, and audit trails - extended to AI workflows rather than reinvented from scratch.
The production gap most teams underestimate
A typical failure pattern looks like this: a product manager demos a chat assistant built with a direct OpenAI call in a view. Stakeholders love it. Engineering adds a few prompt templates. Then traffic arrives, costs spike, one user triggers a policy violation, another receives hallucinated pricing, and nobody can explain which prompt version produced a bad answer from three weeks ago.
Harness engineering closes that gap by treating agents like any other critical subsystem. You define explicit input schemas, cap token budgets per request and per user, route high-risk intents to human review, and store enough metadata to replay and diagnose failures. Django's form validation, serializer layers, and middleware stack map naturally onto these responsibilities.
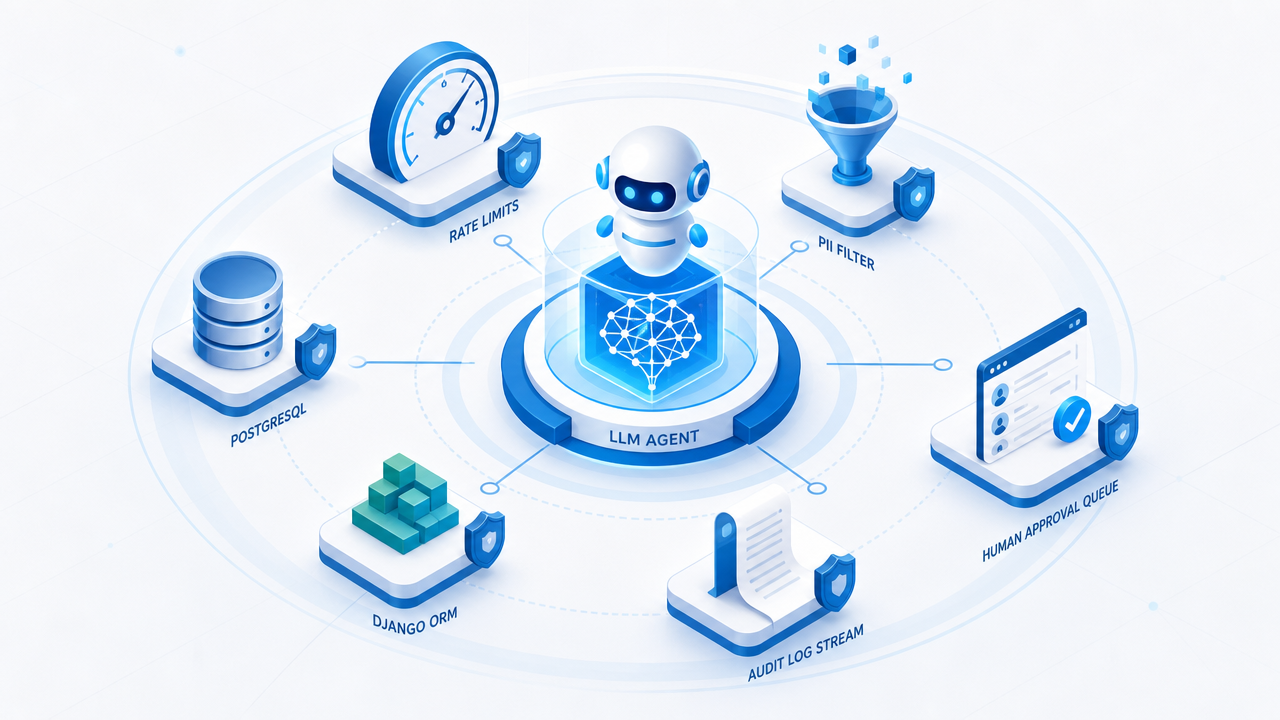
Core harness components we implement on Django projects
- Intent routing: Classify user messages before invoking expensive or sensitive tools. Simple classifiers or lightweight models can gate access to database writes, external APIs, or admin actions.
- Tool boundaries: Agents call whitelisted functions - never raw SQL, never arbitrary shell. Each tool declares required permissions and rate limits enforced at the Django layer.
- Prompt versioning: Store prompts in the database or version-controlled fixtures, linked to deployment tags. Admin users can draft changes; production prompts require review.
- Output validation: Parse LLM responses into Pydantic models or Django forms before persisting or returning them to clients. Reject malformed JSON and retry with constrained prompts.
- Observability: Log prompt hashes, latency, token usage, tool invocations, and user feedback signals. Wire alerts when error rates or cost per session exceed thresholds.
- Graceful degradation: When the model provider is down or slow, fall back to cached answers, simplified flows, or clear error states - never silent failures.
Designing agent workflows that respect Django conventions
We keep agent orchestration in service modules, not in views or model save hooks. A view receives a request, validates input through a serializer, and delegates to an AgentRunner that coordinates retrieval, tool calls, and response assembly. Celery tasks handle long-running agent chains so web workers stay responsive.
Permissions remain explicit. If an agent can create support tickets or modify subscription settings, it runs under the same role checks a human operator would face. Service accounts and scoped API keys prevent a compromised prompt from escalating privilege.
For teams serving US and UK clients, data residency and retention policies belong in the harness layer too. PII redaction before model calls, configurable log retention, and region-specific model endpoints are easier to enforce centrally than in ad hoc view code.
Testing and release discipline
Agent behavior is non-deterministic, but your harness should still be testable. We maintain golden datasets of user queries with expected tool selections and structural output shapes. CI runs these against stubbed model responses so refactors do not regress routing logic. Separate staging environments use real models with synthetic data only.
Canary releases matter. Route a small percentage of traffic to a new prompt version, compare quality metrics and cost, then promote or roll back. Django feature flags - via django-waffle, custom settings, or environment variables - make this straightforward.
When to invest in harness engineering
Not every AI feature needs a full harness on day one. Read-only summarization behind an admin login can start simple. But if agents write to your database, communicate with customers, or influence revenue decisions, invest in harness engineering before launch - not after your first incident.
SparkScribe embeds these patterns into AI automation and Django development engagements for startups and scale-ups. If you are planning agent features for 2026, start with the harness, not the demo.
Incident response when agents misbehave
Despite best efforts, agents will occasionally produce harmful or incorrect output. Your harness should include kill switches that disable specific tools or entire agent flows without redeploying the whole application. Runbooks document who approves re-enabling features, what logs to inspect, and how to communicate with affected users. Post-incident reviews update prompt templates, retrieval filters, or permission scopes - treating agent failures like any other production incident rather than dismissing them as model quirks.
Teams that skip this operational layer often panic-disable AI entirely after the first bad headline, losing product momentum. A measured response preserves user trust and engineering learning. We coach client teams to rehearse rollback scenarios during staging, including provider outages and malformed tool responses, so launch week is not the first time anyone tests the kill switch.
Further reading

Harness checklist for your next sprint
Before merging agent code to main, confirm your team can answer yes to each item below. Gaps here are where production incidents originate.
| Area | Minimum bar |
|---|---|
| Input validation | All user content sanitized; max length enforced |
| Tool access | Whitelisted functions only; permissions checked per call |
| Cost controls | Per-user and global token budgets with hard stops |
| Logging | Prompt version, latency, and outcome stored for replay |
| Human review | Escalation path for high-risk or low-confidence outputs |
| Fallbacks | Defined behavior when models or tools fail |
Treat every LLM response as untrusted input until your harness validates structure, permissions, and business rules - the same way you would treat data from an external API.
Do we need a separate microservice for AI agents?
Usually not at MVP stage. Django plus Celery handles orchestration well for most B2B and consumer apps. Split out a dedicated inference service only when latency, GPU requirements, or team boundaries demand it.
Which Django packages help with harness engineering?
We commonly combine DRF serializers, Celery, Redis for rate limiting, structured logging via django-structlog or similar, and feature flags. The exact stack depends on your compliance needs.
How do we prevent prompt injection from end users?
Separate system instructions from user content, validate outputs before side effects, never give agents tools they do not strictly need, and log suspicious patterns for review.
When should we involve SparkScribe?
If agents touch customer data, payments, or production writes, bring in experienced harness design early. Retrofitting guardrails after launch is slower and riskier than building them in from sprint one.
Ready to stress-test your agent architecture? Contact our engineering team for a technical review or explore how we apply these patterns on client case studies.