

Key takeaways
- Define launch criteria before sprint two not week eleven
- Ship staging CI and monitoring before peak feature velocity
- Integrate payments and email early to avoid launch surprises
- Feature freeze in hardening - fix data and auth bugs first
- Reserve post-launch capacity for traffic-driven fixes
- List exclusions explicitly so timelines stay credible
Article content
Ninety days is enough - if you scope like you mean it
Founders often ask whether three months suffices to go from idea to production. It can - when MVP means minimum viable product, not minimum feature list pulled from competitor screenshots. SparkScribe's ninety-day playbook has taken US and UK startups from discovery to live users on Django backends with React frontends, mobile-ready APIs, and the observability support teams need on day one of real traffic.
This playbook is not a waterfall Gantt chart. It is a sequence of decisions, buffers, and quality gates that prevent the classic failure mode: a demo that impresses investors but collapses when real users register, pay, or trigger edge cases.
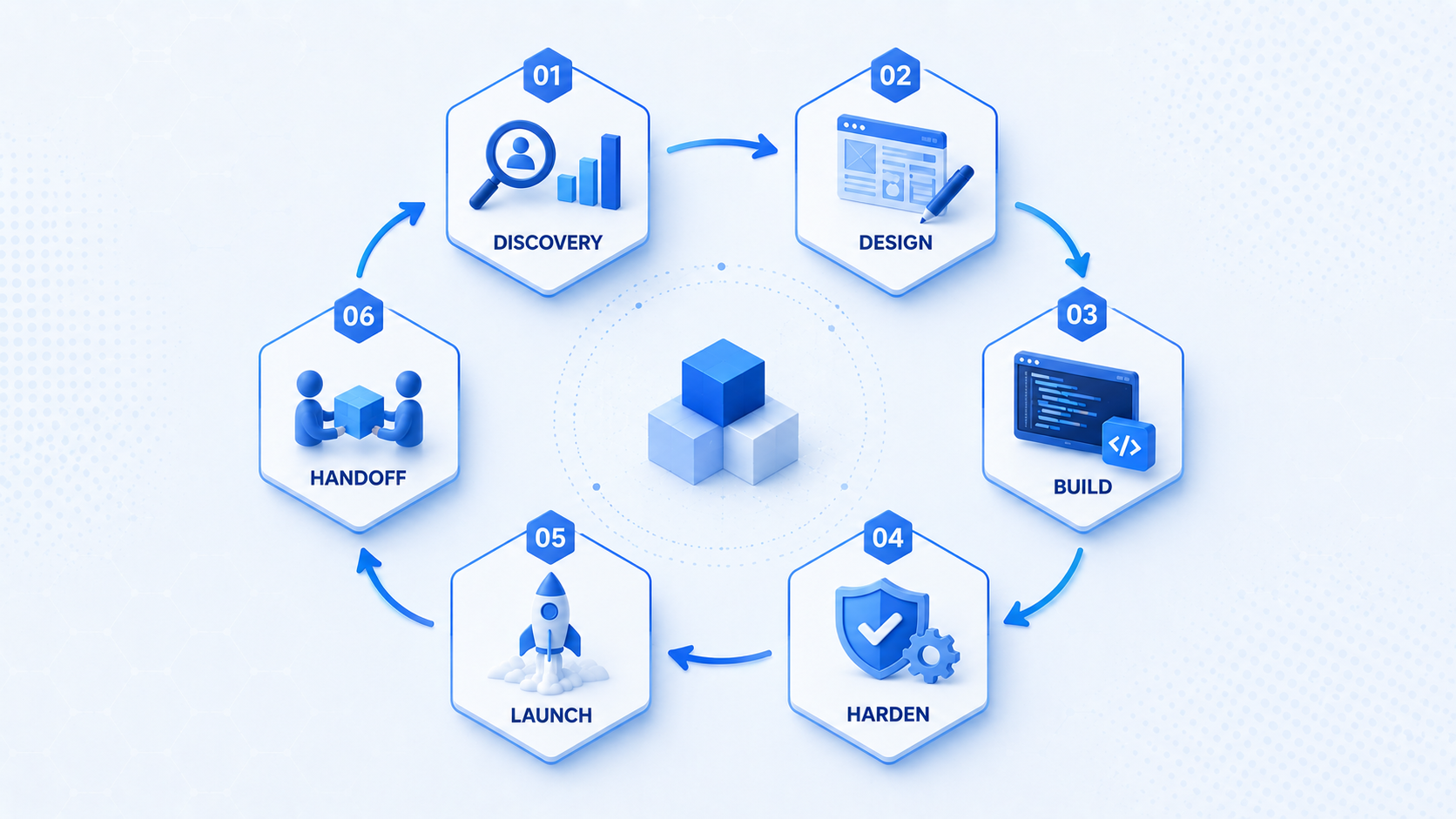
Days 1–21: Discovery, design, and technical foundation
Week one centers on outcomes: who is the user, what action proves value, what must be true on launch day. We map user journeys, identify integrations, and flag regulatory or data constraints. Parallel technical spikes validate risky assumptions - payment flow, legacy API, model latency.
By week three, design systems and API contracts emerge. Django project structure, environments, CI pipeline, and staging deploy exist before feature velocity peaks. Skipping this foundation is how teams reach day sixty with nothing deployable.
Deliverables by end of week three
- Prioritized backlog with MVP and post-MVP labels
- Wireframes or Figma for critical paths only
- OpenAPI or serializer stubs for frontend parallel work
- Staging URL with auth skeleton and error monitoring wired
Days 22–56: Core build sprints
Two-week sprints with demoable increments. Backend teams focus on domain models, permissions, and APIs; frontend teams consume contracts; QA writes tests alongside features rather than at the end. We integrate payments, email, and analytics early - surprises here close to launch kill timelines.
Scope cuts happen here, openly. Nice dashboards defer; broken onboarding does not. Daily async standups plus twice-weekly client syncs keep US and UK stakeholders aligned without meeting fatigue.
Days 57–77: Hardening and beta
Shift toward production readiness: load smoke tests, security review of auth and file uploads, backup verification, runbooks for on-call. Beta users from a friendly cohort stress workflows before marketing announces anything.
Days 78–90: Launch and stabilize
Production deploy with feature flags, monitored rollouts, and rollback plan. Launch communications coordinate support channels. First two weeks post-launch reserve capacity for fixes and performance tuning - traffic patterns reveal what beta missed.
Handoff includes admin documentation, architecture overview, and roadmap recommendations for the next quarter. Many clients transition to retainer capacity rather than pausing engineering entirely.
Roles and client responsibilities
SparkScribe supplies delivery lead, engineers, and QA; clients supply timely decisions, test accounts, and domain expertise. Delayed feedback on designs or legal copy compresses build time nonlinearly. One empowered product owner on the client side is non-negotiable.
What ninety days does not include
Full mobile app store launches, SOC 2 certification, complex data migrations, and large-scale AI training usually exceed this window. We explicitly list exclusions in statements of work so fundraising slides match delivery reality.
Start with a playbook conversation
Every product differs, but the rhythm holds. Review our delivery services, compare timelines on case studies, and contact us with your target launch date - we will map a ninety-day plan or tell you honestly if scope needs trimming.
Metrics we track during the ninety-day window
Sprint velocity alone misleads - we pair it with defect escape rate, staging deploy frequency, and percentage of backlog items meeting acceptance criteria on first demo. Leading indicators of launch risk include growing carry-over work, integration tickets opened late, and environment drift between staging and production. Weekly dashboards shared with founders surface these early enough to cut scope deliberately rather than crash at day eighty-nine.
User metrics wait until beta, but engineering health metrics start week one. Teams ignoring them usually discover insufficient test coverage or missing monitoring only when beta users arrive - exactly when you least want firefighting.
Common ninety-day failure patterns
Unclear product ownership on the client side stalls decisions for days per question. Design perfectionism blocks API contracts frontend could start against. Deferred DevOps yields a “works on my machine” staging environment. Parallel unfocused AI experiments distract from core MVP validation. Naming these patterns during kickoff helps both sides intervene before they compound.
Communication templates that save founders time
We provide weekly written summaries: shipped, in progress, blocked, risks - readable in five minutes between fundraising meetings. Loom demos supplement live calls for stakeholders who cannot attend every sprint review across time zones. Founders who batch feedback into structured comments keep async loops short; scattered Slack messages across days slow India teams disproportionately.
A shared definition of done for MVP - not perfection - keeps ninety-day programs honest when stakeholders debate polish versus launch readiness in week ten.
Further reading

Ninety-day milestone map
| Phase | Days | Exit criteria |
|---|---|---|
| Discovery | 1–21 | Backlog, designs, staging live |
| Core build | 22–56 | MVP flows demoable end-to-end |
| Hardening | 57–77 | Beta feedback incorporated; monitors green |
| Launch | 78–90 | Production deploy; support runbook active |
Can we launch in sixty days instead?
Sometimes for very narrow MVPs with existing design assets. Compression usually cuts beta and hardening - we flag that risk explicitly.
Do you build mobile apps in ninety days?
We often ship API-ready backends plus responsive web; native apps frequently follow in a second phase unless scope is extremely focused.
What happens after day ninety?
Most teams continue on retainer for roadmap items, infrastructure scaling, and AI features planned but deferred from MVP.
How do you handle scope creep?
Change requests swap priority with existing backlog items - net scope increase triggers timeline or budget conversation immediately.
Target a launch quarter? Share your roadmap and we will propose a phased ninety-day statement of work.


